
About Me [ CV ]
|
I am a third-year PHD student in The university of Hong Kong, supervised by Xihui Liu. |
Internship Experience
- 2025.3 - 2026.2, ByteDance. Working on Video VAE and Text-to-Video Generation.
- 2026.2 - present, Tencent. Working on World Model.
Research [ Google Scholar ]
|
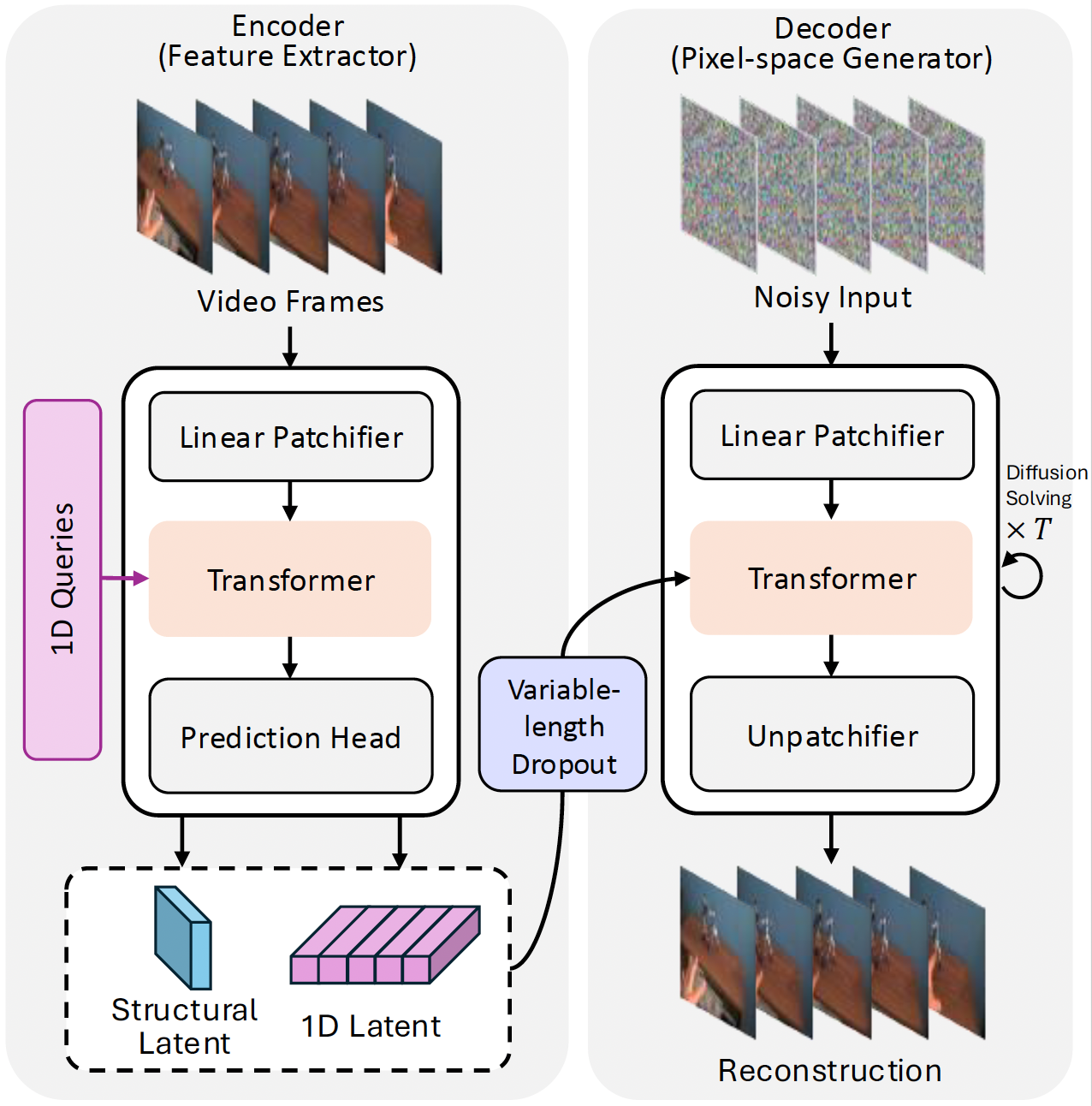
Adaptive 1D Video Diffusion Autoencoder |
|
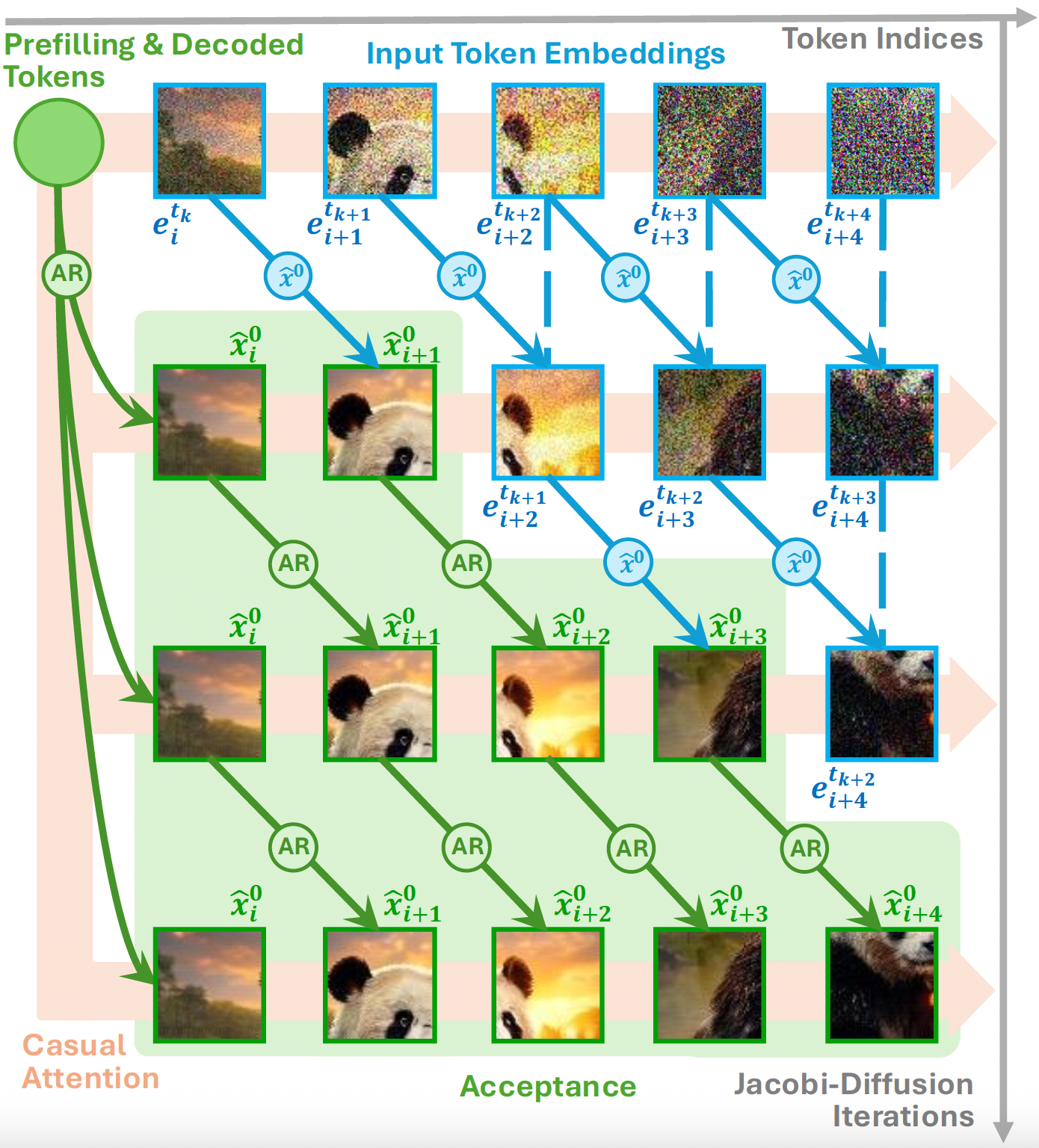
SJD++: Improved Speculative Jacobi Decoding for Training-free Acceleration of Discrete Auto-regressive Text-to-Image Generation |
|
Speculative Jacobi-Denoising Decoding for Accelerating Autoregressive Text-to-image Generation |
|
Accelerating Auto-regressive Text-to-Image Generation with Training-free Speculative Jacobi Decoding |
|
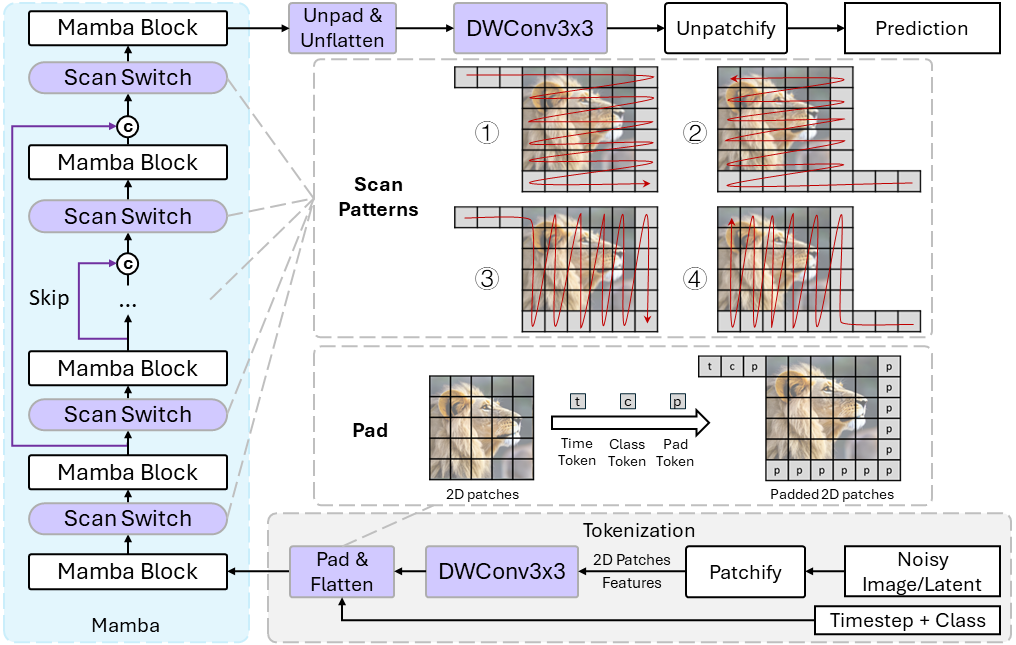
DiM: Diffusion Mamba for Efficient High-Resolution Image Synthesis |
|
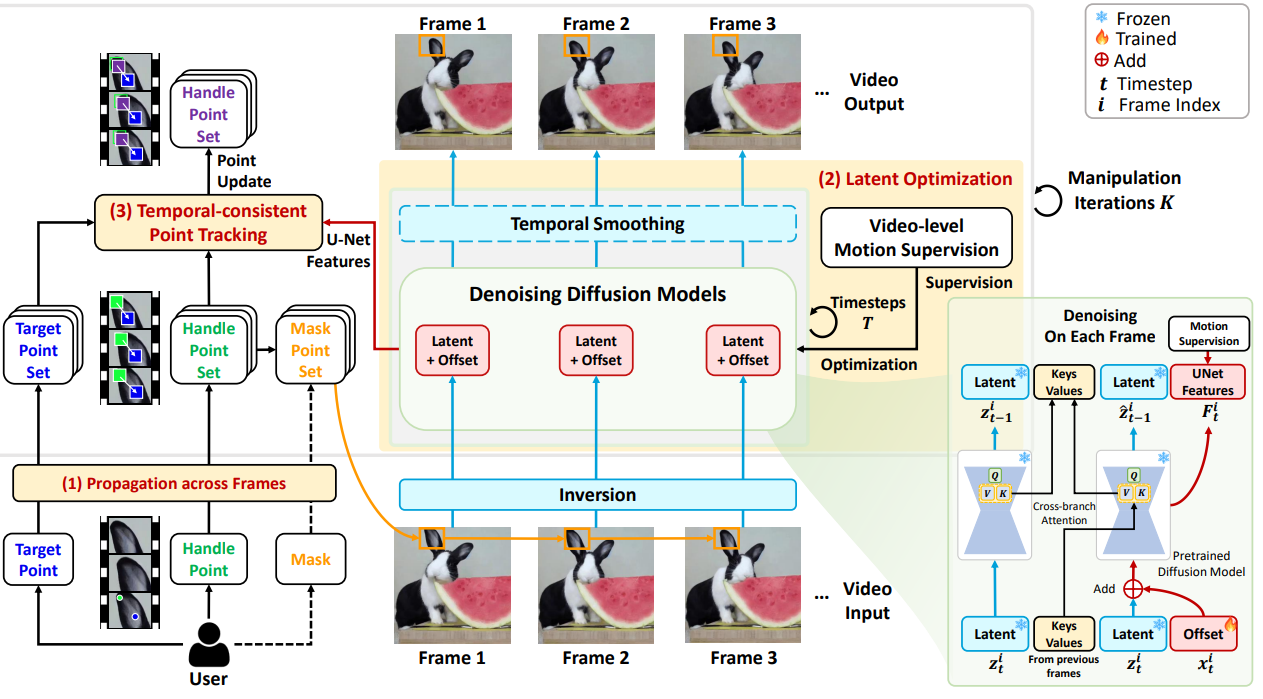
Drag-A-Video: Non-rigid Video Editing with Point-based Interaction |
|
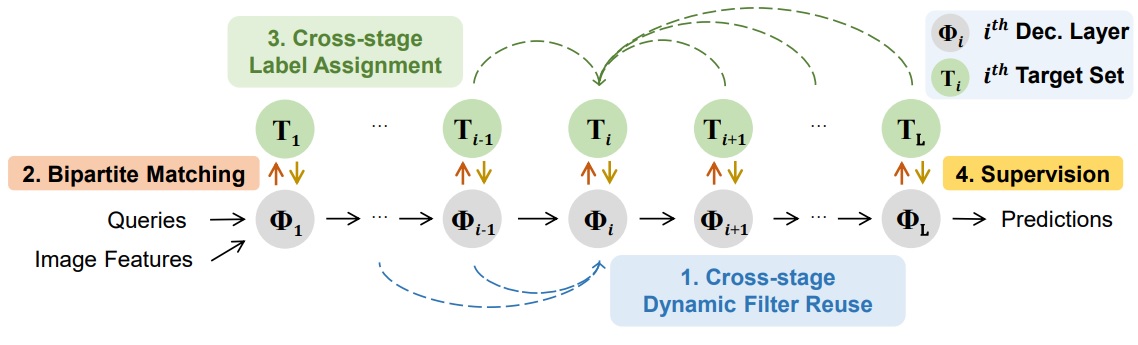
StageInteractor: Query-based Object Detector with Cross-stage Interaction |
|
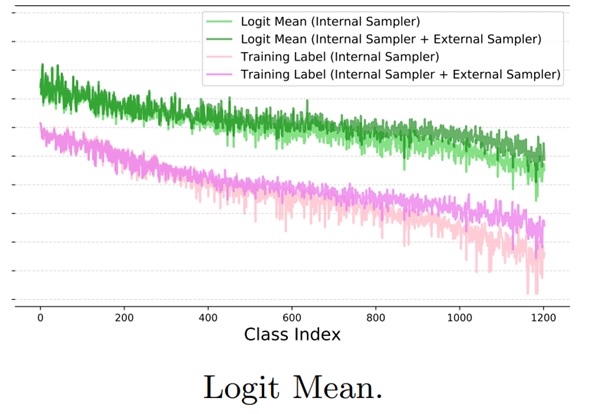
Logit Normalization for Long-tail Object Detection |
|
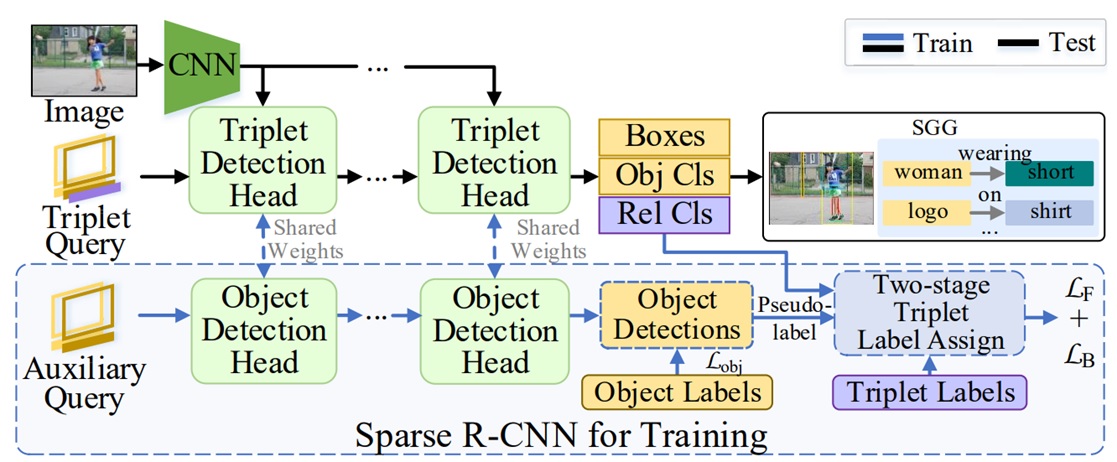
Structured Sparse R-CNN for Direct Scene Graph Generation |
|
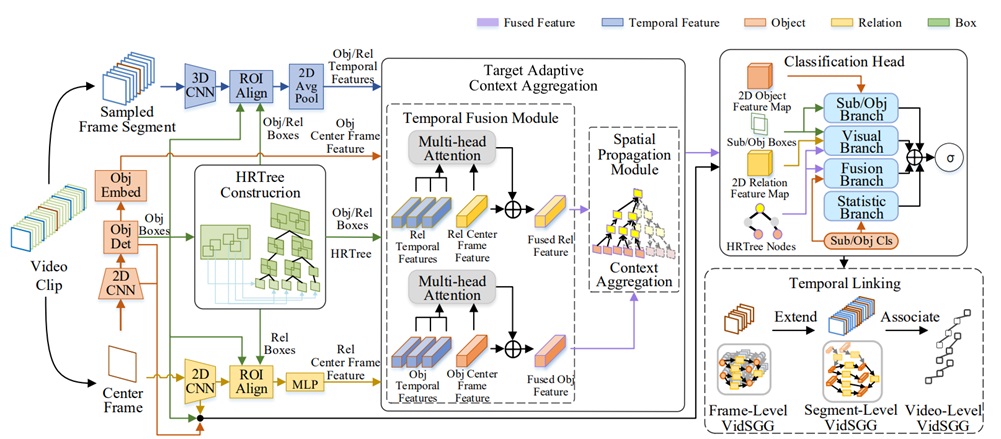
Target Adaptive Context Aggregation for Video Scene Graph Generation |


Selected Awards
- National Scholarship for Postgraduates, Nanjing University, 2021
- Pacemaker to Outstanding Graduate Student, Nanjing University, 2021
- 1st Prize, Scholarship for Postgraduate Students, Nanjing University, 2021
- 2nd Award, University Scholarship, Xidian University, 2016-2018
- Silver Medal, The 2019 ICPC China Shaanxi Provincial Programming Contest, Xidian University, 2019